同步,阻塞
- 同步
- 同步通常是指一个任务的完成依赖于另外一个任务,只有等待被依赖的任务完成后,依赖的任务才能算完成,这是一种可靠的任务序列。要么都成功,要么都失败,两个任务的状态可保持一致。
- 异步
- 异步不需要等待被依赖的任务完成,只是通知被依赖的任务要完成什么工作,该任务就立即执行,只要整个任务完成就算完成了。至于被依赖的任务是否完成,另一任务无法确定,所以是不可靠的任务序列。
- 阻塞
- 阻塞调用是指咋调用结果返回之前,该线程会被挂起,一直处于等待消息通知,不能执行其他任务,在得到结果后返回。
- 非阻塞
- 与阻塞等待结果的方式相反,非阻塞调用若没有在调用后立刻获得调用结果,将会立刻返回。通常非阻塞都会多次调用,所以在提高了CPU利用率的同时,增加了线程切换的次数。
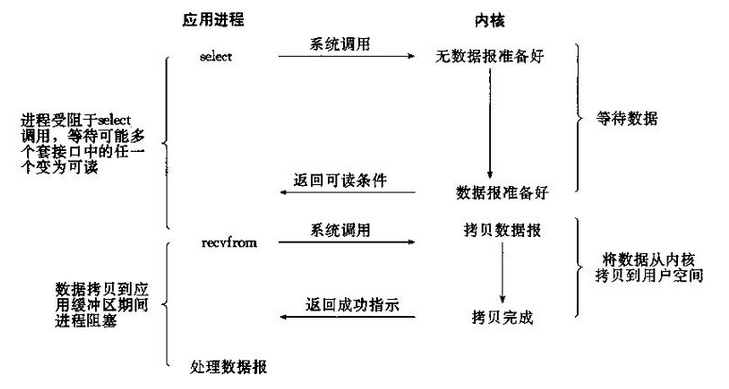
阻塞IO模型
应用程序调用一个IO函数,导致应用程序阻塞,等待数据准备好。从内核拷贝到用户空间,IO函数返回成功指示。
非阻塞IO模型
我们把一个SOCKET接口设置为非阻塞就是告诉内核,当所请求的IO操作无法完成时,不要将进程睡眠,而是返回一个错误。这样我们的IO操作函数将不断的测试数据是否已经准备好,如果没有准备好,继续测试,直到数据准备好为止。
IO复用模型
I/O复用模型会用到select、poll、epoll函数,这几个函数也会使进程阻塞,但是和阻塞I/O所不同的的,这两个函数可以同时阻塞多个I/O操作。而且可以同时对多个读操作,多个写操作的I/O函数进行检测,直到有数据可读或可写时,才真正调用I/O操作函数。
select
select模型维护一个fd_set(File descriptor,long 数组)(维护文件句柄),查询就绪事件并返回。
select系统调用的目的是:在一段指定时间内,监听用户感兴趣的文件描述符上的可读、可写和异常事件。poll和select应该被归类为这样的系统 调用,它们可以阻塞地同时探测一组支持非阻塞的IO设备,直至某一个设备触发了事件或者超过了指定的等待时间——也就是说它们的职责不是做IO,而是帮助 调用者寻找当前就绪的设备。- 优点
在单一线程注册多个socket,并发处理多个IO请求。 - 存在问题
- fd_set在每次调用select都需要拷贝到内核态,拷贝开销大,同时查询操作需要遍历fd_set,速度慢。
- fd_set大小被内核宏定义为1024(32位,64位2048),不可变。
1
2
3
4
5
6
7
8
9
10
11
12
13int select(int nfds, fd_set *readfds, fd_set *writefds,
fd_set *exceptfds, struct timeval *timeout);
void FD_ZERO(fd_set *fdset);
//清空集合
void FD_SET(int fd, fd_set *fdset);
//将一个给定的文件描述符加入集合之中
void FD_CLR(int fd, fd_set *fdset);
//将一个给定的文件描述符从集合中删除
int FD_ISSET(int fd, fd_set *fdset);
// 检查集合中指定的文件描述符是否可以读写
//返回值:失败-1 超时0 成功>0(就绪FD数量)

poll
1 | int poll(struct pollfd *fds, nfds_t nfds, int timeout); |
poll与select差距不大,用pollfd替代fd_set,解决了文件描述符大小上限问题。struct pollfd *fds fds是一个struct pollfd类型的数组,用于存放需要检测其状态的socket描述符,并且调用poll函数之后fds数组不会被清空;一个pollfd结构体表示一个被监视的文件描述符,通过传递fds指示 poll() 监视多个文件描述符。其中,结构体的events域是监视该文件描述符的事件掩码,由用户来设置这个域,结构体的revents域是文件描述符的操作结果事件掩码,内核在调用返回时设置这个域.
epoll
epoll同样只告知那些就绪的文件描述符,而且当我们调用epoll_wait()获得就绪文件描述符时,返回的不是实际的描述符,而是一个代表就绪描述符数量的值,你只需要去epoll指定的一个数组中依次取得相应数量的文件描述符即可,这里也使用了内存映射(mmap)技术,这样便彻底省掉了这些文件描述符在系统调用时复制的开销。
epoll是基于事件驱动的I/O方式,相对于select来说,epoll没有描述符个数限制,使用一个文件描述符管理多个描述符,将用户关心的文件描述符的事件存放到内核的一个事件表中,这样在用户空间和内核空间的copy只需一次。
另一个本质的改进在于epoll采用基于事件的就绪通知方式。在select/poll中,进程只有在调用一定的方法后,内核才对所有监视的文件描述符进行扫描,而epoll事先通过epoll_ctl()来注册一个文件描述符,一旦基于某个文件描述符就绪时,内核会采用类似callback的回调机制,迅速激活这个文件描述符,当进程调用epoll_wait()时便得到通知。
1 | int epoll_create(int size); |
EPOLL无须遍历整个被侦听的描述符集,只要遍历那些被内核IO事件异步唤醒而加入Ready队列的描述符集合就行了。
Epoll的2种工作方式-水平触发(LT)和边缘触发(ET)
- LT:默认工作模式,即当epoll_wait检测到某描述符事件就绪并通知应用程序时,应用程序可以不立即处理该事件;下次调用epoll_wait时,会再次通知此事件.
- ET:当epoll_wait检测到某描述符事件就绪并通知应用程序时,应用程序必须立即处理该事件。如果不处理,下次调用epoll_wait时,不会再次通知此事件。(直到你做了某些操作导致该描述符变成未就绪状态了,也就是说边缘触发只在状态由未就绪变为就绪时只通知一次).
| – | select | poll | epoll |
|---|---|---|---|
| 操作方式 | 遍历 | 遍历 | callback |
| 底层实现 | 数组 | 链表 | 红黑树 |
| IO效率 | 线性遍历o(n) | 线性遍历 o(n) | 事件通知方式,每当fd就绪,系统注册的回调函数就会被调用,将就绪fd放到readyList里面,时间复杂度O(1) |
| 最大链接数 | 1024(x86)或2048(x64) | 无上限 | 无上限 |
| fd拷贝 | 每次调用select,都需要把fd集合从用户态拷贝到内核态 | 每次调用poll,都需要把fd集合从用户态拷贝到内核态 | 调用epoll_ctl时拷贝进内核并保存,之后每次epoll_wait不拷贝 |
信号驱动IO
异步IO
异步通知和异步IO(AIO),用户程序可以通过向内核发出I/O请求命令,不用等待I/O事件真正发生,可以继续做另外的事情,等I/O操作完成,内核会通过函数回调或者信号机制通知用户进程。这样很大程度提高了系统吞吐量。