内存分配方式

栈
栈内存分配运算内置于处理器的指令集中,效率很高,但是分配的内存容量有限。堆
手动delete,程序结束后,OS自动回收。堆是一块连续的内存区域。这块内存区域的起始位置和结束位置,并且这块连续的内存区域可以被程序员随意使用,并且这块区域是很大。全局/静态存储区
未初始化全局区和已初始化全局区
存储内容
栈:在栈中,第一个进栈的是主函数下一条指令的地址,然后是函数的各个参数,在大多数编译器中,参数是由右往左入栈,然后是函数中的局部变量。注意,静态变量不入栈。出栈则刚好顺序相反。
堆:一般在堆的头部用一个字节存放堆的大小,具体内容由程序员安排。
LINUX 系统调用函数
大内存各种malloc基本上都是直接mmap的。而对于小数据,则通过向操作系统申请扩大堆顶,这时候操作系统会把需要的内存分页映射过来,然后再由这些malloc管理这些堆内存块,减少系统调用。而在free内存的时候,不同的malloc有不同的策略,不一定会把内存真正地还给系统,所以很多时候,如果访问了free掉的内存,并不会立即Run Time Error,只有访问的地址没有对应的内存分页,才会崩掉。
brk()和sbrk()
1 |
|
- brk()和sbrk()改变程序间断点的位置。程序间断点就是程序数据段的结尾。(程序间断点是为初始化数据段的起始位置).通过增加程序间断点进程可以更有效的申请内存 。当addr参数合理、系统有足够的内存并且不超过最大值时brk()函数将数据段结尾设置为addr,即间断点设置为addr。sbrk()将程序数据空间增加increment字节。当increment为0时则返回程序间断点的当前位置。
- brk()成功返回0,失败返回-1并且设置errno值为ENOMEM(注:在mmap中会提到)。sbrk()成功返回之前的程序间断点地址。如果间断点值增加,那么这个指针(指的是返回的之前的间断点地址)是指向分配的新的内存的首地址。如果出错失败,就返回一个指针并设置errno全局变量的值为ENOMEM。
- 这两个函数都用来改变 “program break” (程序间断点)的位置,改变数据段长度(Change data segment size),实现虚拟内存到物理内存的映射。
- brk()函数直接修改有效访问范围的末尾地址实现分配与回收。
- sbrk()参数函数中:当increment为正值时,间断点位置向后移动increment字节。同时返回移动之前的位置,相当于分配内存。当increment为负值时,位置向前移动increment字节,相当与于释放内存,其返回值没有实际意义。当increment为0时,不移动位置只返回当前位置。参数increment的符号决定了是分配还是回收内存。
- brk和sbrk分配的内存需要等到高地址内存释放以后才能释放,无法直接释放,需要按照顺序。
mmap()
当开辟的空间大于128k时,mmap()系统调用函数来在虚拟地址空间中(堆和栈中间,称为文件映射区域的地方)找一块空间来开辟。
mmap是一种内存映射文件的方法,即将一个文件或者其它对象映射到进程的地址空间,实现文件磁盘地址和进程虚拟地址空间中一段虚拟地址的一一对映关系。实现这样的映射关系后,进程就可以采用指针的方式读写操作这一段内存,而系统会自动回写脏页面到对应的文件磁盘上,即完成了对文件的操作而不必再调用read,write等系统调用函数。相反,内核空间对这段区域的修改也直接反映用户空间,从而可以实现不同进程间的文件共享。
1 | void *mmap(void *start, size_t length, int prot, int flags, int fd, off_t offset); |
参数说明:
成功执行时,mmap()返回被映射区的指针。失败时,mmap()返回MAP_FAILED[其值为(void *)-1], error被设为以下的某个值:
1 | 1 EACCES:访问出错 |
start:映射区的开始地址
length:映射区的长度
prot:期望的内存保护标志,不能与文件的打开模式冲突。是以下的某个值,可以通过or运算合理地组合在一起
1
2
3
41 PROT_EXEC :页内容可以被执行
2 PROT_READ :页内容可以被读取
3 PROT_WRITE :页可以被写入
4 PROT_NONE :页不可访问fd:有效的文件描述词。如果MAP_ANONYMOUS被设定,为了兼容问题,其值应为-1
flags:指定映射对象的类型,映射选项和映射页是否可以共享。它的值可以是一个或者多个以下位的组合体
offset:被映射对象内容的起点
SGI STL 的 allocator
- STL 包含一级配置爱和二级配置器,对于大于128bytes的空间,直接使用第一级配置器第一级配置器以malloc(),free(),realloc()等C函数执行实际的内存配置、释放、重新配置等操作,并且能在内存需求不被满足的时候,调用一个指定的函数。
- 小于128bytes的内存申请,使用内存池进行管理。基本思路是设计一个free_list[16]数组,负责管理从8bytes到128 bytes不同大小的内存块(chunk),每一个内存块都由连续的固定大小(fixed size block)的很多chunk组成,并用指针链表串接起来。当用户要获取此大小的内存时,就在free_list的链表找一个最近的free chunk回传给用户,同时将此chunk从free_list里删除,即把此chunk前后chunk指针链结起来。用户使用完释放的时候,则把此chunk放回到free_list中,放到最前面的start_free的位置。这样经过若干次allocator和deallocator后,free_list中的链表可能并不像初始的时候那么是chunk按内存分布位置依次链接的。假如free_list中不够时,allocator会自动再分配一块新的较大的内存区块来加入到free_list链表中。
ptmalloc(glibc)
- ptmalloc 包含一个主分配区和多个非主分配区(非主分配区智能通过mmap()申请内存)。 当某个线程调用malloc的时候,会先查看线程私有变量中是否已经存在一个分配区,如果存在则尝试加锁,如果加锁失败则遍历arena链表试图获取一个没加锁的arena, 如果依然获取不到则创建一个新的非主分配区。
- 分配的内存在ptmalloc中使用chunk表示,每个chunk至少需要8个字节额外的开销。用户free掉的内存不会马上归还操作系统,ptmalloc会统一管理heap和mmap区域的空闲chunk,避免了频繁的系统调用。
- ptmalloc将相似大小的chunk用双向链表链接起来,这样的一个链表被称为一个bin。Ptmalloc 一共维护了128个bin,并使用一个数组来存储这些bin。
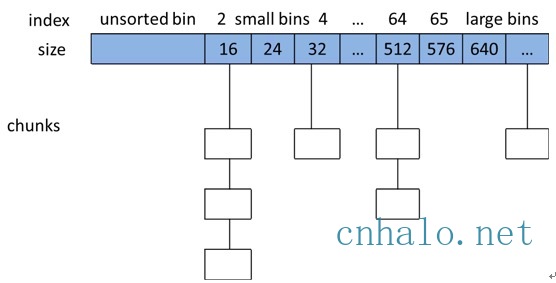
- 数组中的第一个为 unsorted bin, 数组中从 2 开始编号的前 64 个 bin 称为 small bins, 同一个small bin中的chunk具有相同的大小。small bins后面的bin被称作large bins。
分配步骤

- 在free的时候,ptmalloc会检查附近的chunk,并尝试把连续空闲的chunk合并成一个大的chunk,放到unstored bin里。
- 但是当很小的chunk释放的时候,ptmalloc会把它并入fast bin中。同样,某些时候,fast bin里的连续内存块会被合并并加入到一个unsorted bin里,然后再才进入普通bin里。
- 所以malloc小内存的时候,是先查找fast bin,再查找unsorted bin,最后查找普通的bin,如果unsorted bin里的chunk不合适,则会把它扔到bin里。
- Ptmalloc的分配的内存顶部还有一个top chunk,如果前面的bin里的空闲chunk都不足以满足需要,就是尝试从top chunk里分配内存。如果top chunk里也不够,就要从操作系统里拿了。
- 特别大的内存,会直接从系统mmap出来,不受chunk管理,这样的内存在回收的时候也会munmap还给操作系统。
回收free
和分配过程反过来,加上一些chunk合并和从一个bin转移到另一个bin的操作。如果顶部有足够大的空闲chunk,则收缩堆顶并还给操作系统。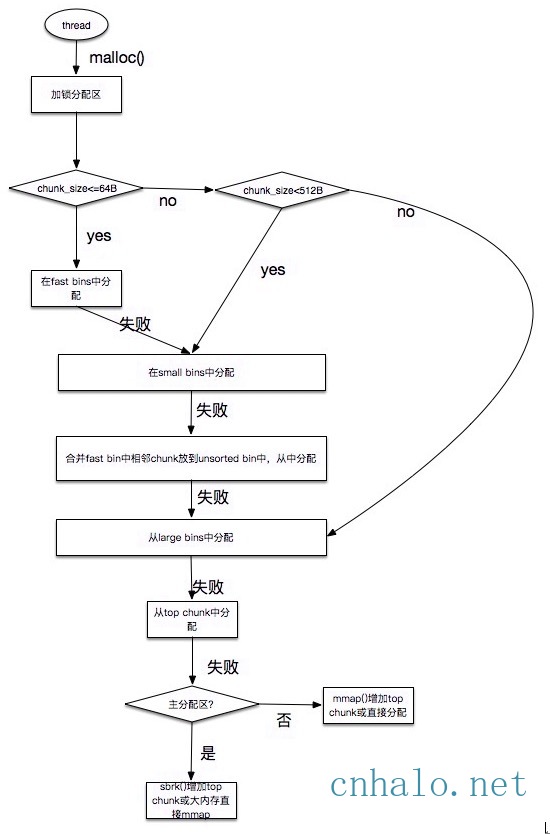
缺点
- Ptmalloc默认后分配内存先释放,因为内存回收是从top chunk开始的,top chunk无法释放时,其他的也无法释放。
- 多线程频繁分配和释放内存,会造成频繁加解锁。
- 不定期分配长生命周期的内存,容易造成内碎片,影响内存回收。

tcmalloc(google thread cache malloc(线程缓存分配器))

其内存管理分为线程内存和中央堆两部分。
小对象分配
对于小块内存分配,其内部维护了几十个不同大小的分配器,和ptmalloc不同的是,它的每个分配器的大小差是不同的,依此按8字节、16字节、32字节等间隔开。在内存分配的时候,会找到最小复合条件的,比如833字节到1024字节的内存分配请求都会分配一个1024大小的内存块。如果这些分配器的剩余内存不够了,会向中央堆申请一些内存,打碎以后填入对应分配器中。同样,如果中央堆也没内存了,就向中央内存分配器申请内存。
在线程缓存内的60个分配器(_文档上说60个,但是我在2.0的代码里看到得是86个_)分别维护了一个大小固定的自由空间链表,直接由这些链表分配内存的时候是不加锁的。但是中央堆是所有线程共享的,在由其分配内存的时候会加自旋锁(spin lock)。
在线程内存池每次从中央堆申请内存的时候,分配多少内存也直接影响分配性能。申请地太少会导致频繁访问中央堆,也就会频繁加锁,而申请地太多会导致内存浪费。在tcmalloc里,这个每次申请的内存量是动态调整的,调整方式使用了类似把tcp窗口反过来用的慢启动(slow start)算法调整max_length,每次申请内存是申请max_length和每个分配器对应的num_objects_to_move中取小的值的个数的内存块。
num_objects_to_move取值比较简单,是以64K为基准,并且最小不低于2,最大不高于32的值。也就是说,对于大于等于32K的分配器这个值为2(好像没有这样的分配器 class),对于小于2K的分配器,统一为32。
大内存分配
对于大内存分配(大于8个分页, 即32K),tcmalloc直接在中央堆里分配。中央堆的内存管理是以分页为单位的,同样按大小维护了256个空闲空间链表,前255个分别是1个分页、2个分页到255个分页的空闲空间,最后一个是更多分页的小的空间。这里的空间如果不够用,就会直接从系统申请了。
分页管理
Tcmalloc使用一种叫span的东西来管理内存分页,一个span可以包含几个连续分页。一个span的状态只有未分配(这时候在空闲链表中),作为大对象分配,或作为小对象分配(这时候span内记录了小对象的class size)。
在资源释放的时候,首先计算其分页编号,然后再查找出它对应的span,如果它是一个小对象,则直接归入小对象分配器的空闲链表。等到空闲空间足够大以后划入中央堆。如果是大对象,则会把物理地址连续的前后的span也找出来,如果空闲则合并,并归入中央堆中。
jemalloc(facebook)
Jemalloc 把内存分配分为了三个部分,第一部分类似tcmalloc,是分别以8字节、16字节、64字节等分隔开的small class;第二部分以分页为单位,等差间隔开的large class;然后就是huge class。内存块的管理也通过一种chunk进行,一个chunk的大小是2^k (默认4 MB)。通过这种分配实现常数时间地分配small和large对象,对数时间地查询huge对象的meta(使用红黑树)。
Jemalloc在64bits系统上使用下面的size-class分类:
- Small: [8], [16, 32, 48, …, 128], [192, 256, 320, …, 512], [768, 1024, 1280, …, 3840]
- Large: [4 KiB, 8 KiB, 12 KiB, …, 4072 KiB]
- Huge: [4 MiB, 8 MiB, 12 MiB, …]
small/large对象查找metadata需要常量时间, huge对象通过全局红黑树在对数时间内查找。
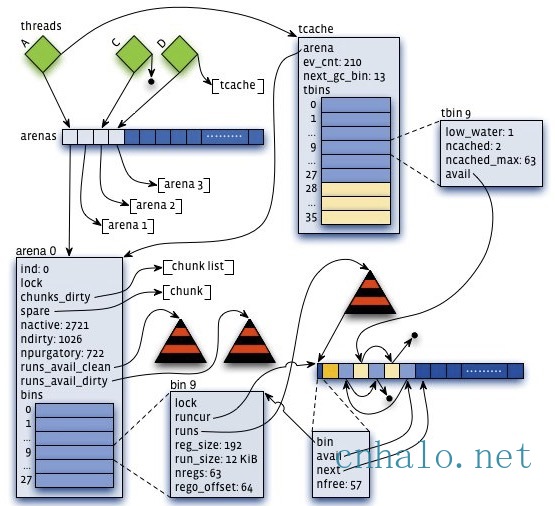
虚拟内存被逻辑上分割成chunks(默认是4MB,1024个4k页),应用线程通过round-robin算法在第一次malloc的时候分配arena, 每个arena都是相互独立的,维护自己的chunks, chunk切割pages到small/large对象。free()的内存总是返回到所属的arena中,而不管是哪个线程调用free()。
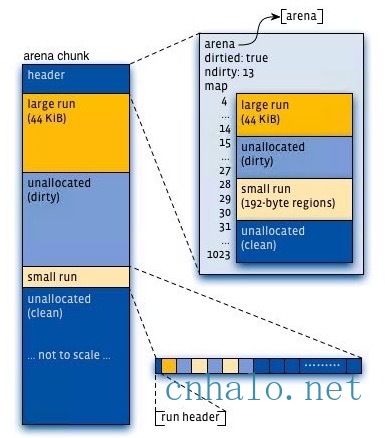
Jemalloc也使用了分配区(arena)来维护内存。线程按第一次分配small或者large内存请求的顺序Round-Robin地选择一个分配区。每个分配区都维护了一系列分页,来提供small和large的内存分配请求。并且从一个分配区分配出去的内存块,在释放的时候一定会回到该分配区。
每个分配区内都会包含meta信息,记录了其对应的chunk列表,每个chunk的头部都记录了chunk的分配信息。在使用某一个chunk的时候,会把它分割成很多个run,并记录到bin中。不同size的class对应着不同的bin,这点和前面两种分配器一样。在bin里,都会有一个红黑树来维护空闲的run,并且在run里,使用了bitmap来记录了分配状态。
和前面两种分配器不同的是,分配区会同时维护两组run的红黑树,一组是未被分配过内存(clean区域),另一组是回收的内存(dirty区域)。而且不是前面那两种分配器所使用的链表。同样,每次分配,都是选取最小且符合条件的内存块。但是优先从dirty区域查找。
由于分配区的设计和ptmalloc差不多。在访问分配区的时候需要对其加锁,或者对某一个size的bin加粒度更小的锁。为了减少锁征用,这里又参照tcmalloc引入了线程缓存。并且其线程缓存的垃圾回收机制和tcmalloc一样,也是基于分配请求的频率自动调整的。线程缓存的结构就像一个简化版的arena,加了一些垃圾回收的控制信息。

- 小内存(small class): 线程缓存bin -> 分配区bin(bin加锁) -> 系统调用
- 中型内存(large class):分配区bin(bin加锁) -> 系统调用
- 大内存(huge class): 直接mmap组织成N个chunk+全局huge红黑树维护(带缓存)